プロダクション環境でElasticsearch+kibana(fluentd)でログ可視化運用をしてみてわかった事
これは Elasticsearch Advent Calendar 2014 22日目の記事です。
今回は、プロダクション環境で、流行りのFluentd+Elasticsearch+Kibanaでログ可視化というのを数ヶ月やった中で苦労した点とかはまった点を書いてみます。 というか、書き終えて思うとこれからやる人はここに気をつけた方がいいというような内容になってしまったので、既に運用されている方にはあまり役に立たないかもです。。
内容は、大きく下記3つです。
①集計(検索)の条件を考えてtemplateでnot_analyzeを指定しておく
②スキーマ変更があるindexは、日単位でindex作るべし
③数値型フィールドの罠(Fluentd寄りの話)
前提として、この流れで収集しているのは下記4パターンのログ達。
・Apache accesslog ・Apache errorlog ・Application log ・Mysql slowlog
①集計(検索)の条件を考えてtemplateでnot_analyzeを指定しておく
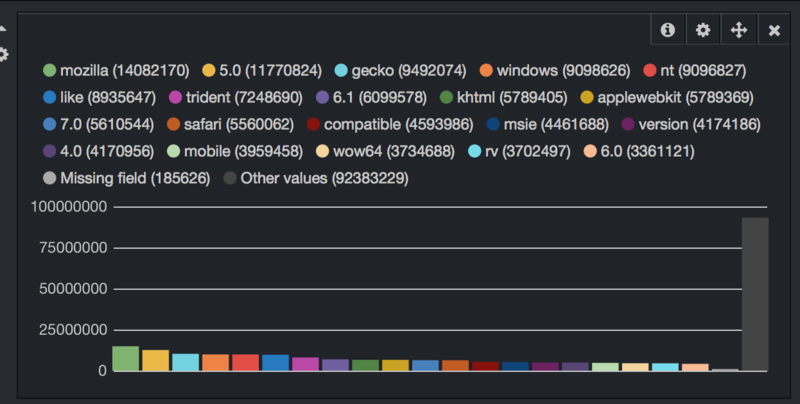
ログをElasticsearchに入れるような環境では、例えばUser-Agentで下記のようにランキングを出したりしたいと思います。 只、スキーマを定義せずにtermとかでランキングをカウントするととても悲しい事が起こる。。 要は、下記の画像のような状態。 分かち書きされた単語毎にカウントされて全く意味のないランキングが出来る。。
スキーマ定義なし
分かち書きされたものがランキングされてとても悲しい意味のないランキングとなっている
スキーマ定義あり
これが出したいランキングの形!
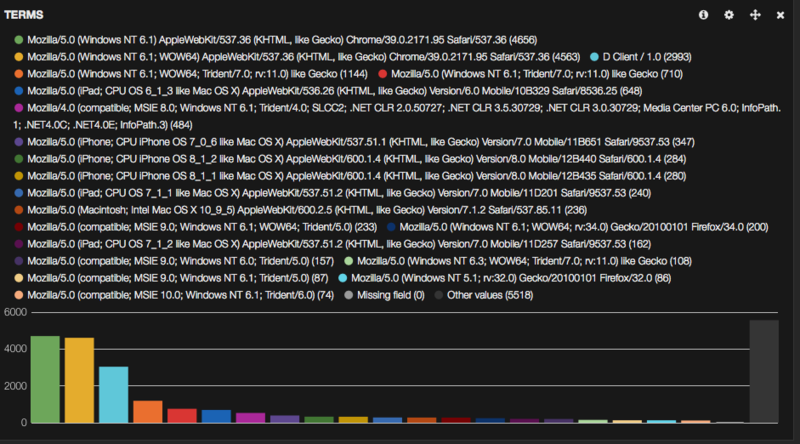
なので、index作成前に下記のような形でElasticsearchのテンプレートを登録しておく。 今回の例でいうとagentというフィールドを分かち書きしないで格納(not_analyzed)したいので、下記3パターンのいずれかのテンプレートを適用する。
ちなみに、kibanaでランキング簡単に表示するのは、Panel Typeに「terms」を指定して、下記のように集計したいフィールドを指定するだけで簡単に出るので素晴らしい。
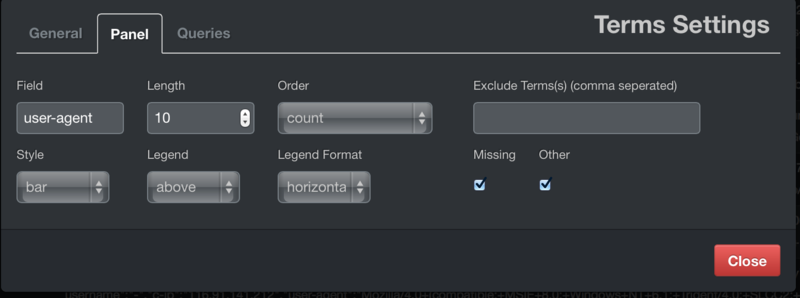
パターン1 agentを分かち書きなしのみで登録したい
{
"template":"weblog-*",
"order":"1",
"mappings":{
"_default_":{
"_source":{"compress":true},
"propaties":{
"agent":{"type":"string","index":"not_analyzed"},
"code":{"type":"integer"},
"size":{"type":"integer"},
"restime":{"type":"integer"}
}
}
}
}
パターン2 agentは分かち書きなしにしたいが、分かち書きありも必要
multi_fieldという形式でテンプレート定義する事で、特定フィールドに複数のスキーマを適用出来る kibana等で検索する場合は、[full.agent:AAA]のような形で指定すると分かち書きされたフィールドが対象になる
※今回の例だとこちらのフィールドを指定してtermでグラフ作成すれば意図したUser-Agent一覧が出る
agent:分かち書きされたフィールドが対象になる
{
"template":"weblog-*",
"order":"1",
"mappings":{
"_default_":{
"_source":{"compress":true},
"propaties":{
"agent":{"type":"multi_field",
"fields":{
"agent":{"type":"string","index":"analyzed"},
"full":{"type":"string","index":"not_analyzed"}
}
},
"code":{"type":"integer"},
"size":{"type":"integer"},
"restime":{"type":"integer"}
}
}
}
}
パターン3 一つ一つ定義するのは面倒臭いので、string型を全て分かち書きしないようにする
dynamic_template(特定のフィールドタイプに対して全て同じスキーマを当てるイメージ)というElasticsearchが提供している素敵な機能を使う
{
"template":"weblog-*",
"order":"1",
"mappings":{
"_default_":{
"_source":{"compress":true},
"dynamic_templates":[{"string_template":{"match":"*","mapping":{"type":"string","index":"not_analyzed"},"match_mapping_type":"string"}}],
"propaties":{
"code":{"type":"integer"},
"size":{"type":"integer"},
"restime":{"type":"integer"}
}
}
}
}
適用方法も一応書いておく。
#weblog_templateというテンプレートを登録 $ curl -XPUT localhost:9200/_template/weblog_template -d "`cat ~/template1.json`" #下記コマンドでweblog_templateの中身を確認し意図したものが適用されてるか確認 $ curl -XGET "localhost:9200/_template/weblog_template?pretty"
次回index作成時に、elasticseach-headとかでmetadataを見てテンプレートがあたったかを見てみる
②スキーマ変更があるindexは、日単位でindex作るべし
fluent-plugin-elasticsearchを使って収集したログをElasticsearchに突っ込むわけですが、デフォルトでは下記のように日単位でindexが作られます。
config_param :logstash_dateformat, :string, :default => "%Y.%m.%d"
デフォルトで使ってればよかったんですが、メンテンスを考えるとindex数は少ないほうが楽という勝手な思い込みで下記の様に、月単位でindexを作成
logstash_dateformat %Y.%m
ちなみに、全ログを同じように月単位indexしてました。
ところが、、ある日、 下記のような声がチームから聞こえてきました。。
「Application logに新しい項目を追加します」
「Access logに新しい項目追加します」
elasticsearchはスキーマレスなので、どんなデータでも突っ込む事は出来ますが、デフォルトだとanalyzeされてstring型で格納されます。 只、kibanaでログ解析のようなシーンで使いたい場合は、①で書いたようにデータをanalyze(分かち書き)せずに格納して使いたいシーンが多いと思います。
Fluentd側で収集する部分直せばElasticsearchに突っ込む事は出来ますが、テンプレートを作りなおしても、
適用されるのは新規index作るタイミング=1ヶ月に一回なのでそれまで新しい項目を有効に使えないという事実に直面しました。
結局は、そのタイミングでindexを日単位にする修正を入れたのですが、サービスインしている中でバックアップ取ってindexを作り直すのは辛かったので、スキーマ変更のあるログを扱う際は特段理由のない場合は、
日単位でのindex作成がおすすめかと思います。
※既にあるインデックスに対しても、ElasticsearchのAPI経由でスキーマ変更可能と@johtaniからコメントをいただきました。その手順も下記に書いてみたのでご参考までに。
日毎でインデックスを作って、リリース前にAPIで既存インデックスにマッピングを追加しておく事で無駄データを作らず、新規項目をすぐに使える運用が出来るかなと思います。
Elasticsearchで既にあるインデックスのスキーマを変更する方法 - shnagaiのインフラ備忘録
③数値型フィールドの罠(Fluentd寄りの話)
ログには当然数値として扱って分析したデータもあります。例えば、access logのレスポンスタイムとか。 只、これも考えれば当然の話なのですが下記のようなトラブルに遭遇しました。
当初、②の流れに沿ってrestime(レスポンスタイム)というフィールドにintegerタイプをテンプレートとしてあてたので、kibana上から下記のようなクエリを投げてレスポンスタイム3秒以上のリクエストをグラフ化しようとしたところ、レコードが一件もヒットしない事態が発生しました。。。
restime:[3000000 TO *]
なぜだ、、、
しばらく色々調べて気づいたのですが、Fluentdがログをパースする段階では全てのキーをstringとして扱うので、Elasticsearchとしては、Stringをintegerとしては格納出来ず上記のようなクエリが効かない状態になっていました。
なので、私の場合はログをパースするwebサーバのfluentd側の設定で、下記のようにtypesを使いrestimeを数値型に変換して、Fluentdの収集サーバに渡すようにしました。
※収集側でももちろんtypecast とかを使えば変換可能ですが、収集側にElasticsearchも同居しているという負荷を考え収集元で変換するようにしています。
types restime:integer
これで、Elasticsearch側でもテンプレートが効いて、restimeを数値としてフィールド登録するようになり無事3秒以上のリクエストを可視化する事に成功しました。
他にも、書きたいことはいくつかありますが、長くなってきたので今回はこの辺にしておこうと思います。
所感をまとめると、Elasticsearchはスキーマレスではあるけれど、ログをつっこむにあたっても事前にどう分析したいかを検討した上で、テンプレートを作成して意図したデータを取り出せるようにするのが重要だなーと思いました。
まだ、収集したものをそこまで効果的に活用出来ていないので、Elasticsearchの動向を見守りつつ意味あるログ基盤を作っていこうと思います。